Level 2 Autonomous Driving on a Single Device: Diving into the Devils of Openpilot
by Li Chen1, Tutian Tang2, Zhitian Cai1, Yang Li1, Penghao Wu3, Hongyang Li1, Jianping Shi, Junchi Yan1, Yu Qiao1 from preprint arXiv:2206.08176, 2022.
Abstract
目前大多数量产解决方案仍处于 Level 2 阶段,售价$999 的 Comma.ai 提供了基于单目摄像头的端到端L2 自动驾驶能力。
本文探究了Comma.ai 的自动驾驶开源项目 Openpilot,其内部模型称为Supercombo,但训练过程和数据没有完全开源。
本文尝试重新实施训练细节并在公共基准测试中进行测试。 这项工作中提出的重构网络称为 OP-Deepdive,并引入了双模型部署方案来测试现实世界中的驾驶性能。
本文希望分享我们的最新发现,从工业产品层面阐明端到端自动驾驶的新视角,并可能激发社区继续改进。我们的资料在 https://github.com/OpenPerceptionX/Openpilot-Deepdive
Introduction
A combination of the super-powered computational chip and sensors usually cost more than 10, 000 U.S. dollars.
Openpilot 使用了一个端到端网络Supercombo 而不是传统模块化的感知、决策和规划单元。
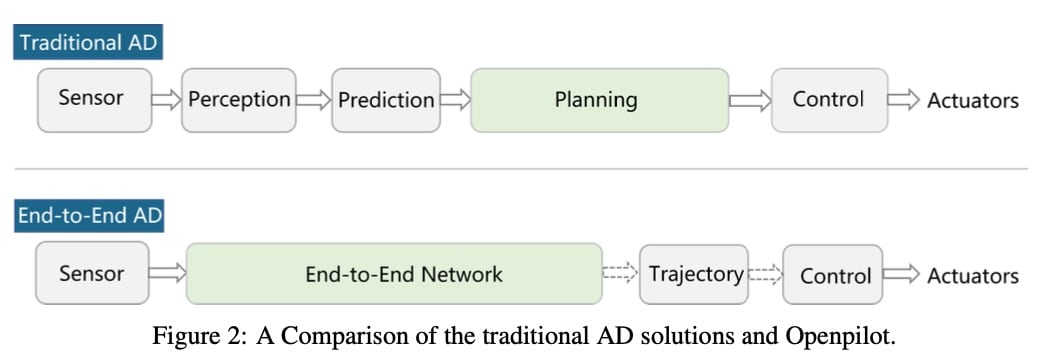
学术界已经有了很多端到端的尝试:Learning from all vehicles. In CVPR, 2022.
其在模拟环境例如CARLA 中的表现很好,但是在真实世界中的结果是未知的,Openpilot 的成功也许能同时激励学术界和工业界关于端到端的热情,遗憾的是,训练细节以及大量的数据都没有向公众公布。
本文建立了自己的端到端模型,即OP-Deepdive,我们的预处理和后处理与openpilot一致。我们分析了底层逻辑,并提出了一个双模型部署框架,成功地在设备上运行了我们自己的模型。
数值结果表明,原始 Supercombo 和我们重新实现的OP-Deepdive 在高速公路场景下都能很好地执行,但在街道场景下却不成立。在定量指标方面,我们的模型与原始的openpilot 模型是一致的。车载性能测试进一步表明,开放式驾驶系统适用于封闭道路(高速、普通道路等),是一种优秀的自动驾驶辅助系统。
预曲
总览
Comma.ai 提供了4个功能:
- Adaptive Cruise Control (ACC)
- Automated Lane Centering (ALC)
- Forward Collision Warning (FCW)
- Lane Keeping Assist (LKA)
其支持了150多种汽车。
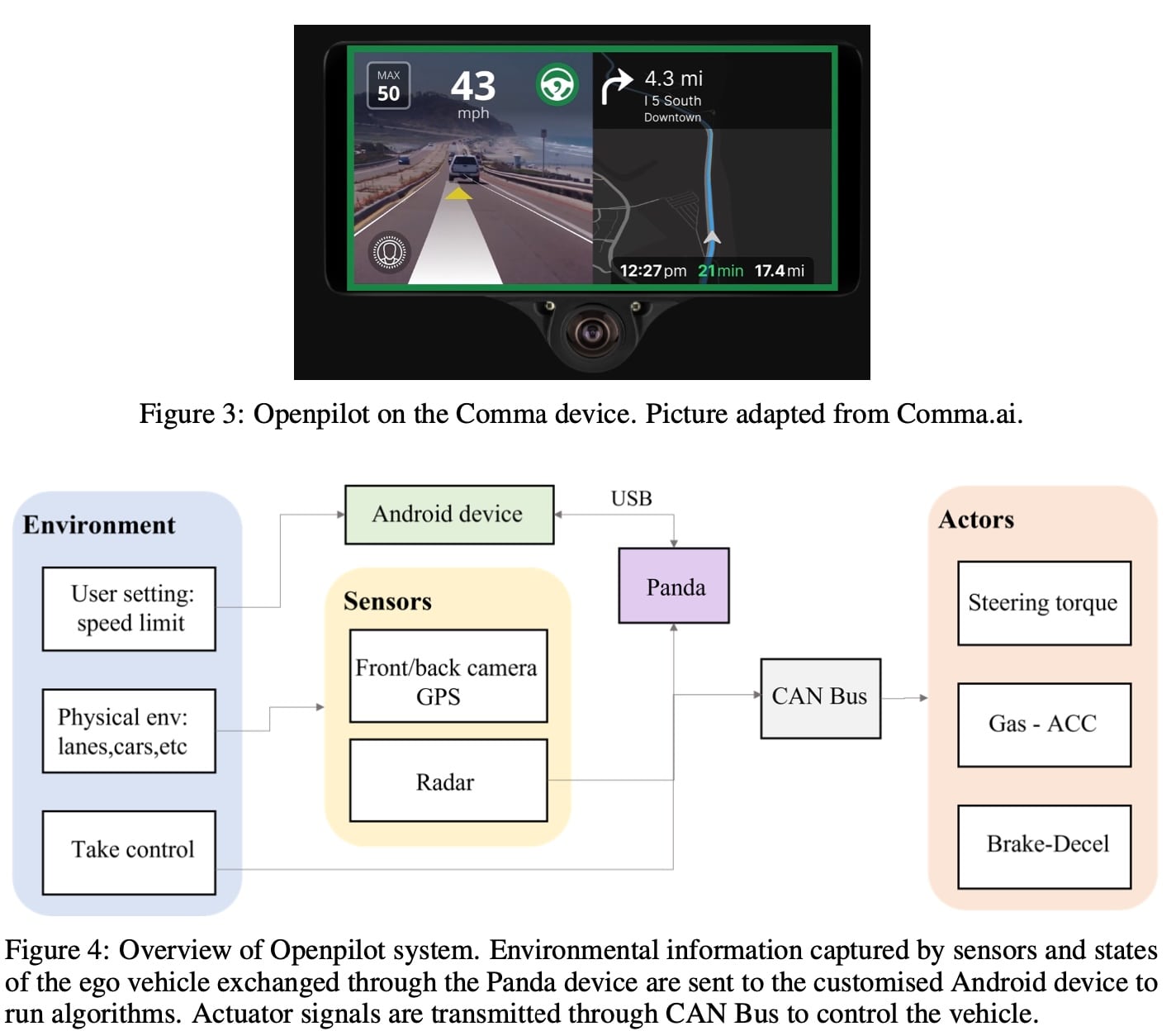
Openpilot 主要由软件和硬件两部分组成。软件部分包括各种算法和中间件。这个名为EON 的硬件设备充当一整套设备的大脑,负责运行系统 (高度定制的android系统) 和软件算法。整个系统架构如图4所示。ENO 设备上的不同单元捕获相应的环境信息,例如,一个摄像头拍摄物理世界的正面图像,一个名为panda的汽车接口从CAN总线提取车辆的状态。在这一步中还使用了车辆上的库存雷达。然后,利用这些数据,openpilot运行Supercombo 模型,并通过后处理软件和中间件验证其输出。最后通过panda 接口向车载控制器发送控制信号。
Panda https://blog.comma.ai/a-panda-and-a-cabana-how-to-get-started-car-hacking-with-comma-ai/
The Supercombo Model
Supercombo is the perceptual algorithm
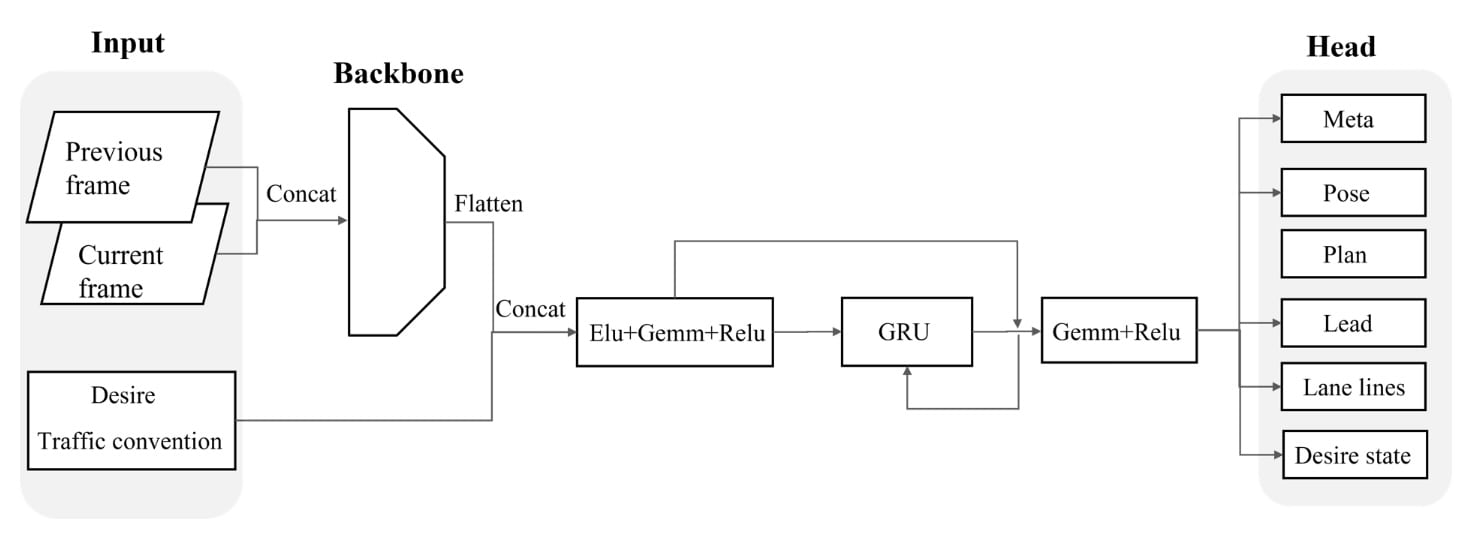
它以两个连续的帧作为输入,一个向量表示所需的高级命令,一个布尔值表示左右交通约定。最终的预测包括计划的轨迹、自我姿态、车道线、先导车状态等。
Elu: Exponential Linear Unit x>0 ? x : α∗(exp(x)−1)
Gemm:通用矩阵乘(GEMM) https://zhuanlan.zhihu.com/p/66958390
GRU(Gate Recurrent Unit):https://zhuanlan.zhihu.com/p/32481747
-
预处理
首先,将 (3 × 256 × 512) 的原始单帧3通道 rgb图像转换为尺寸为 (6 × 128 × 256) 的6通道yuv格式。然后,将两个连续的帧连接在一起作为模型输入,得到(12 × 128 × 256)的输入大小。
-
主要的网络
骨干网采用谷歌的 Efficientnet-B2 https://zhuanlan.zhihu.com/p/240205612,性能好,效率高。该算法采用群卷积的方法,减少了主链中参数的数量。为了获取时间信息,一个GRU 被连接到骨干网络。
-
预测头
几个全连接层都附加到 GRU,充当预测头。 输出包括5条可能的轨迹,其中置信度最高的一条被选为计划轨迹。 每个轨迹包含自车辆坐标系下的 33 个 3D 点的坐标。 此外,Supercombo 还可以预测车道线、道路边缘、前方物体的位置和速度等车辆的一些其他信息。
方法
An End-to-end Planning Model
对于训练所需的一些数据不容易获得,例如领先汽车的位置和速度。 因此,我们对输入和输出格式做了一些改动,输入帧通过主干并被展平为长度为 1024 的特征向量。然后,该向量被送入宽度为 512 的 GRU 模块,使模型能够记住时间信息。 最后,几个全连接层将网络输出组织成所需的格式。
-
预处理 - 透视变换
Openpilot要求用户在安装后做一个摄像头校准过程,在此过程中驾驶员需要手动驾驶车辆沿着长而直的道路行驶一段时间,并保持相对固定的速度。还有一个在设备工作时保持运行的在线校准过程,以在悬架系统产生振动的情况下保持外部参数的更新。 一旦知道了外部因素,我们就可以进行简单的图像变形操作,使图像看起来像从标准相机拍摄的图像。
-
预处理 - 颜色变换
Openpilot directly reads raw images from the CMOS, and uses the YUV-422 format as the model input to reduce the overhead overhead,但是公开的MP4 视频本身就是RGB,所以我们不进行转换。
-
骨干网
EfficientNet-B2,给定 (6, 128, 256) 的输入tensor,主干输出形状为 (1408, 4, 8) 的tensor。 然后,具有 3 × 3 内核的卷积层将通道数减少到 32。最后,形状为 (32, 4, 8) 的张量被展平为长度为 1024 的特征向量。
-
GRU
宽度为 512 的 GRU,预测时间。
-
预测头
在 GRU 模块之后,几个全连接层负责根据需要组织输出维度。 Supercombo 模型将产生一个长度为 6609 的张量作为最终输出。 预测包括计划轨迹、预测车道线、道路边缘、前车位置和一些其他信息。 然而,由于目前没有提供所有这些注释的数据集,我们只关注重新实现中的计划轨迹。
令 M 为可能轨迹的数量。 每条轨迹由N个3D点在本车坐标系下的坐标和一个置信度数组成。 那么,输出维度 D 是,
D = M × (N × 3 + 1)
通常,我们有M = 5和N = 33。考虑到国际单位下坐标的原始值比较大,我们对所有x坐标添加一个指数函数,对所有y坐标添加一个sinh函数。
-
损失函数
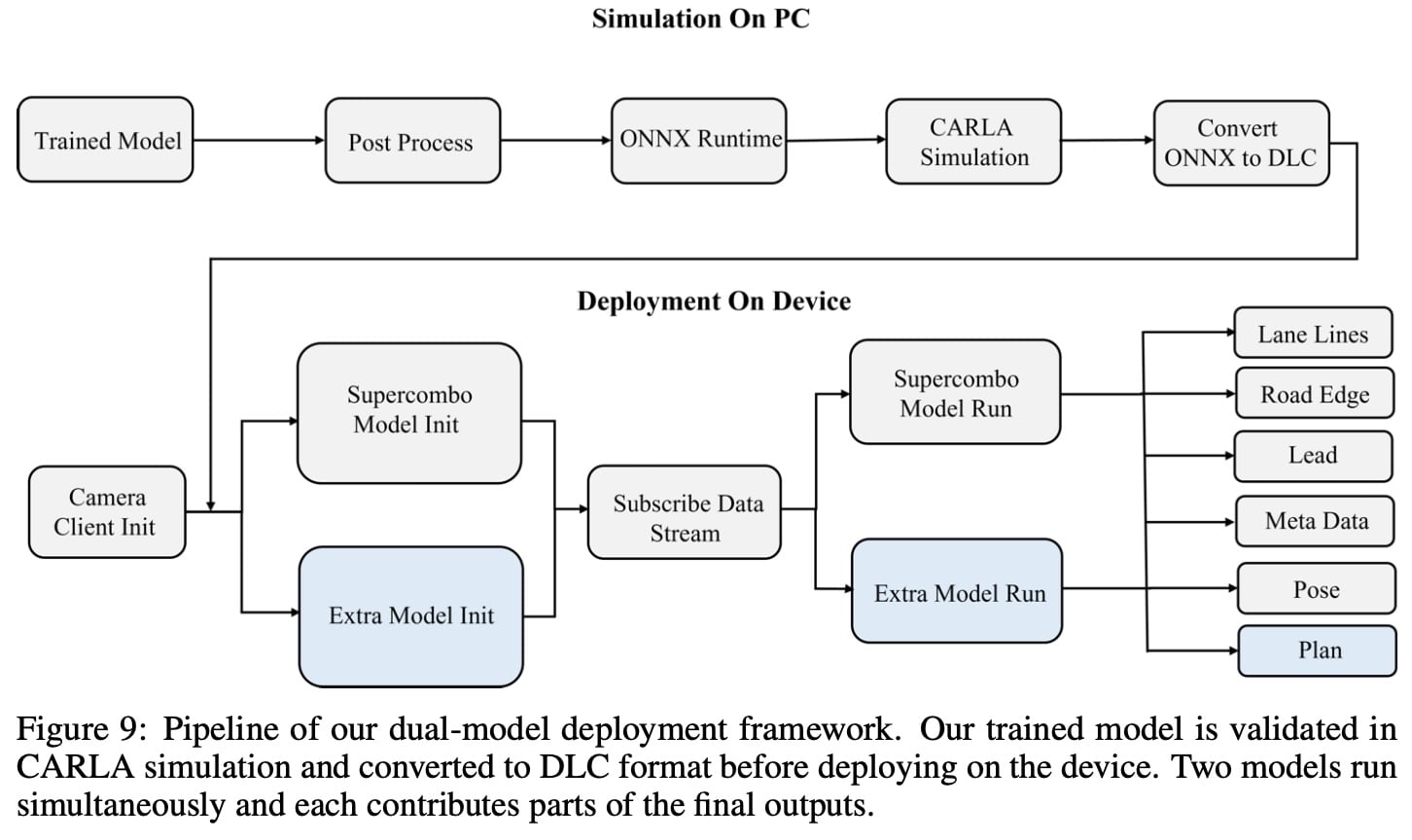
设备部署
我们设计了双模型部署方案。两个模型都部署在开发板上,并交替进行预测。 具体来说,我们将Supercombo 预测的轨迹替换为我们模型预测的轨迹,其他信息保持不变。
讨论
Open-loop v.s. Closed-loop
本文的系统以开环方式进行训练和测试,该模型只是学习人类最有可能的行为,模型甚至没有机会学习如何从错误中恢复。
其次,它可能会引入一种特征泄漏。 在某些情况下,如果车辆当前正在加速,模型将预测更长更快的轨迹,反之亦然。这表明该模型是从驾驶员的驾驶意图而不是道路特征中学习的。
闭环训练和测试的障碍在于我们根本做不到。 允许未经良好训练的车辆根据其预测轨迹在道路上行驶太危险,因此不切实际。 有两种解决方法。 第一个是在 Comma.ai 的博客中介绍的。 我们可以通过WARP机制模拟闭环训练和测试,使得从一个视角采集的图像看起来像是从不同视角采集的。 第二个是在模拟器中完全训练和测试模型。 然而,这两种解决方案都不是完美的,因为 WARP 机制会引入图像伪影,而现有的模拟器 [13] 无法渲染逼真的图像。
模仿度量
本文使用两个模仿指标(即平均欧氏距离误差和平均精度),但模仿学习的指标应该是多样的。
从可能犯错的人类行为中学习可能本身就有问题,而且行为的选择可能是多样的(超车/跟车)
“Debug” an End-to-end Model
难以对全融合的模块进行调试。例如,如果模型拒绝在红灯时停车,我们如何知道它是否成功检测到红灯和停车线?
