Integrated Decision and Control for High-Level Automated Vehicles by Mixed Policy Gradient and Its Experiment Verification
中国国际科技合作项目(2019)资助项目(e0100200),中国资助项目(51575293),中国资助项目(u20 a20334)。它也得到了清华大学-丰田汽车自动化汽车技术联合研究中心的部分支持。 From: 没出版? By: Yang Guan#1 , Liye Tang#1, Chuanxiao Li1, Shengbo Eben Li*1 , Yangang Ren1 , Junqing Wei2, Bo Zhang2, Keqiang Li1 Demo 视频:https://space.bilibili.com/363124977 Github : https://github.com/idthanm/env_build
Abstract
!Self-evolution.e.g Tesla Autopilot
This paper presents a self-evolving decisionmaking system based on the Integrated Decision and Control (IDC), an advanced framework built on reinforcement learning (RL)
-
RL algorithm called constrained mixed policy gradient (CMPG,约束混合策略梯度) -> consistently upgrade the driving policy of the IDC.
- adapts the MPG under the penalty method
- solve constrained optimization problems using both the data and model.
-
an attention-based encoding (ABE) -> tackle the state representation issue
- an embedding network for feature extraction
- a weighting network for feature fusion
- fulfilling order-insensitive encoding and importance distinguishing of road users
-
通过融合CMPG和ABE,我们开发了第一个IDC架构下的数据驱动决策和控制系统,并将该系统部署在日常运行的全功能自动驾驶汽车上。
Introduction
该模块接收来自汽车的八个摄像头的图像,并输出不同的感知方面,例如地图的鸟瞰图、检测到的物体及其属性、信号灯等。
核心是一个称为 HydraNet 的多任务神经网络,以及从其自动驾驶模式或影子模式收集的大量标记数据。每次从主干后添加一个任务,然后用影子数据训练。
决策系统在过去20发展的三个流派:
-
基于规则
基于规则的系统将决策功能划分为几个子功能,例如预测、行为选择和轨迹规划。这种设计简单明了,有助于协作。但其升级严重依赖有限的人类知识,从而导致高事故率。
-
数据驱动的
数据驱动系统旨在通过监督学习来适应决策网络。其中输入是感知结果,输出是车辆命令。这样的系统可以实现自我进化,但它需要收集无穷无尽的标记数据以保证在极端情况下的安全性,这几乎是不可能的。
-
大脑启发的
近年来,类脑系统逐渐受到关注和发展。这样的系统不依赖标记数据,而是从零开始学习驾驶,并通过反复试验慢慢成长为专家级驾驶员。集成决策和控制 (IDC) 架构是这一类别的代表。
但是IDC没有自我进化的能力:
- 用于解决 CMDP 问题的 RL 算法是基于模型的,因此最终的性能只与先验环境模型有关,无法随着时间的推移而提高。
- 其次,CMDP问题的状态编码是任务指定的,其中 the order of interested road users of different tasks 需要由专家单独分配。
本文在IDC架构下构建了一个自我进化的决策系统:
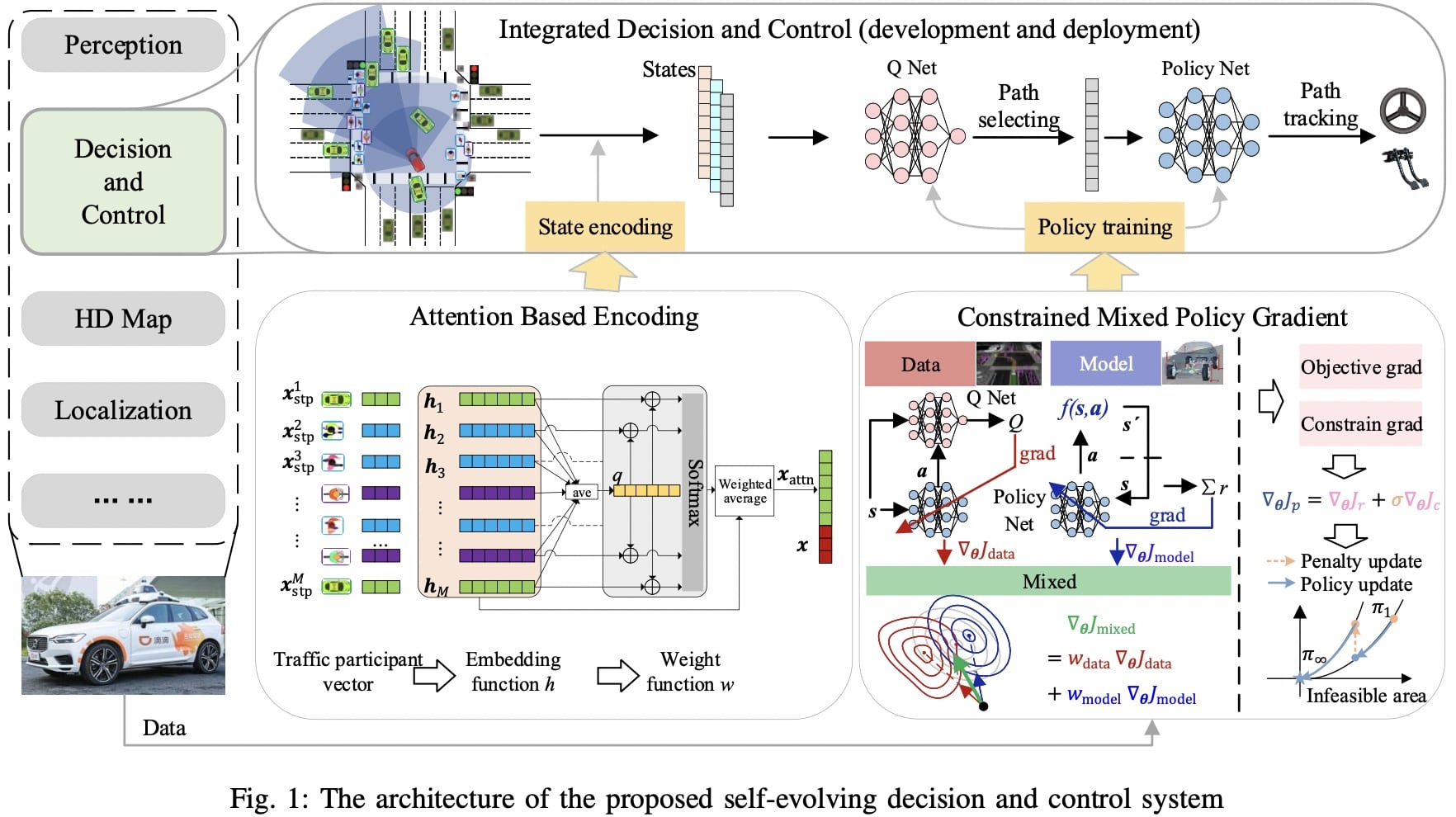
这些贡献有三个部分:
- 提出了约束混合策略梯度(CMPG)算法来解决IDC的CMDP问题。 CMPG 是一种为约束优化而设计的 RL 算法。与基于模型的算法不同,CMPG 可以同时使用交互数据和先验模型来有效且一致地改进自动驾驶策略。
- 设计了一种基于注意力的状态编码(ABSE)方法来解决一般情况下道路使用者的表示。 ABSE 建立了一个顺序不敏感的编码网络来处理动态流量,同时捕获各个参与者的相对重要性。证明了该方法的单射性质。
- 我们通过在IDC架构中融合CMPG和ABSE。它是世界上第一个部署在日常运营自动驾驶汽车中的数据驱动的决策和控制系统。该系统的性能在一个混合交通流的真实信号交叉口进行了验证。
Related work
RL 广泛运用于自动驾驶, It models the autonomous driving as a CMDP by designing state, action and reward.
Early attempts mainly concentrated on learning single driving tasks, e.g, lane-keeping, lane-changing, or overtaking
Recently, it has been employed in specific scenarios with more complex surroundings and tasks, such as intersection, multi-lane , ramp, or roundabout (环形交叉路口) -> need carefully designed task-coupled rewards & not strictly safe ( collision as a soft consideration )
RL as the offline solver to ensure real-time performance. However, self-evolution is still not fulfilled because of the model-based algorithm and the lack of general state representation.
RL 通常被分为数据驱动&模型驱动,前者的问题是是数据局部性导致收敛缓慢,后者的问题是性能通常会受到模型误差的影响。
CMPG
CMPG 算法的目标是通过数据和模型解决约束问题。 基本思想是首先通过惩罚方法将问题转化为无约束优化。 然后利用 MPG 估计变换后的目标函数的梯度。 最后通过梯度下降实现策略更新。 外点法不需要目标函数的凸性,所以我们考虑用它来处理约束。 使用它,我们通过添加违反约束的惩罚项将原始问题转换为无约束问题,整个问题是一个约束求解。
ABSR
Autonomous driving state representation
自动驾驶汽车(ADC)的决策主要受其自身动力学特性、周围交通参与者(STP)、道路类型、参考路径和交通信号的影响。
STP 的表示存在维度和排列敏感问题,而其他元素可以很容易地解释为固定维度向量 [31]。
Attention-based encoding layer
ABE 利用注意力机制对 STP 的重要性进行建模,并应对灵活的 STP 问题。
Injective property of ABE
The dynamic optimal tracking problem of IDC is an online optimization problem -> poor computioan efficiency
应用 CRL 实际上可以离线解决问题,从而减轻计算压力。 原始 OCP 转换为 CMDP 问题。 为了保证这两个问题的等价性并保持策略的最优性,表示函数UABE需要是一个injective 的单射性质.
Policy Learning and Simulation Verification
……
任务评估
速度曲线表明所提出的方法可以很好地平衡跟踪和安全性能,其中 ADC 在与其他没有冲突的情况下达到目标速度。控制曲线(加速度和转向角)代表了其在时空空间中出色的运动平滑性和灵活的协调性。最后,它实现了很高的计算效率
首先,可以从通过时间(图 12a)和转向角(图 12b)中观察到任务的多样性。对于前者,由于ADC在直行任务中不需要显式与行人和骑自行车的人交互,因此通过时间低于左转和右转任务。而对于后者,显然是在不同的任务中将方向盘转向不同的方向,由于其转弯半径较小,右转的幅度通常大于其他方向。另一方面,我们可以通过速度误差(图 12c)和加速度(图 12d)发现交通组成的影响。混合交通场景中较大的速度误差说明 ADC 可以通过自适应牺牲跟踪性能来保证不同难度场景中的驾驶安全。类似的现象也反映在加速度上,在混合交通条件下其方差要大得多,这归因于 ADC 频繁的避撞反应。总体而言,所提出的方法可以很好地应对大量环境变化以进行合理的驾驶行为。
Terminology
什么是 end-to-end 神经网络?
https://www.zhihu.com/question/51435499
不再是分阶段的提取feature,而是让网络自己学习如何抓取feature效果更佳。
通过缩减人工预处理和后续处理,尽可能使模型从原始输入到最终输出,给模型更多可以根据数据自动调节的空间,增加模型的整体契合度。
Shadow Mode
https://cloud.tencent.com/developer/news/360341
影子模式的核心在于在有人驾驶状态下,系统包括传感器仍然运行但是不进行控制,用来跑算法模型、对其进行验证。算法在“影子”中持续做模拟决策,并且把决策与驾驶员的行为进行对比。会出现两种情况,一种是完全一致,那其实啥也没学到;一种是显著不同,这样又会产生两种情况,一种是驾驶员出了问题,对驾驶员提出警报,一种是算法不够完善,需要从当前的情况学习新的控制策略。这里面其实存在一个可怕的逻辑,那就是还存在一个高于驾驶员和机器的存在,来判断到底是谁做的好,来帮助机器做下一步决策。
再说回第一种情况,算法给出的决策和人一致,这个难道就是可信的吗?经常开车的朋友可能知道,路上多的是不好好开车的人,好好开车人的比例少之又少,这已经不是克服噪声的问题,而是好的学习范例被淹没在了噪声当中,恐怕即使能学,也会是个让人惶恐不敢坐上去的车。
回顾特斯拉AutopilotAI总监AK上任以来的报告
