Which Tasks Should Be Learned Together in Multi-task Learning?
Standley T, Zamir A, Chen D, et al.[C] from International Conference on Machine Learning. PMLR, 2020: 9120-9132.
https://zhuanlan.zhihu.com/p/517869181
Abstract
-
background
NN can solve mutiple tasks simultaneously -> save inference time(推理时间) -> also lead to global performance declining (compete between multitask)
-
What we did
propose a framework for assigning tasks to a few neural networks such that cooperating tasks are computed by the same neural network, while competing tasks are computed by different networks. 用来分配任务的框架
Introduction
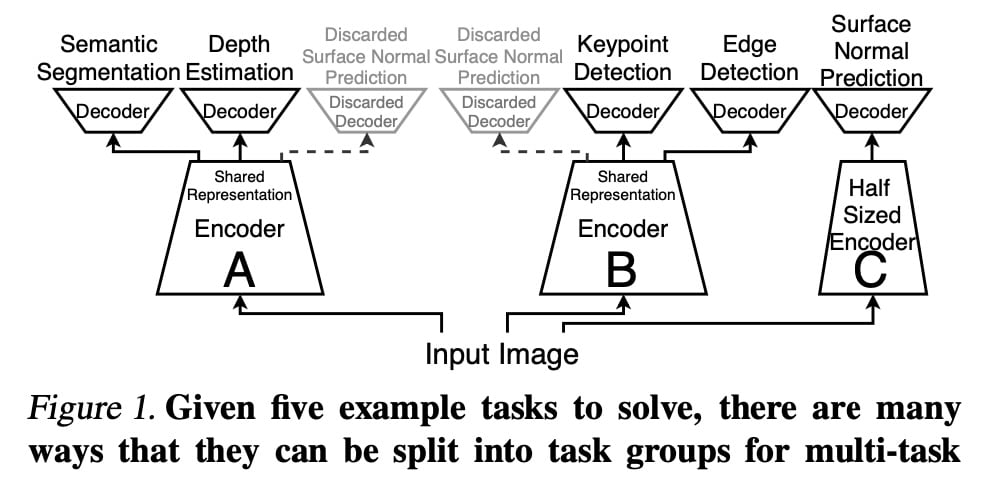
问题
In fact, multitask performance can suffer so much (负迁移效益) that smaller independent networks are often superior.
- the tasks must be learned at different rates.
- one task may dominate the learning leading to poor performance on other tasks.
- task gradients may interfere and multiple summed losses may make the optimization landscape more difficult.
Prior work
这种质量的损失或获得似乎取决于联合训练的任务之间的关系。
we find that transfer relationships are not highly predictive of multi-task relationships
two clusters of contemporary techniques hard parameter sharing and soft parameter sharing.
- 硬参数共享中,网络中的大部分或全部参数在所有任务之间共享。
- 软或部分参数共享中,每个任务要么有一组单独的参数,要么有很大一部分参数是未共享的。
...
更加细致的分类: https://zhuanlan.zhihu.com/p/138597214
与我们的方法不同,上述工作都没有试图发现好的任务组来一起训练。 此外,软参数共享不会减少推理时间,这是我们的主要目标。
How we did it?
将竞争任务分配给单独的网络&将合作任务分配给同一网络
我们开发了一个计算框架,用于选择将最佳任务组合在一起,以便拥有少量独立的神经网络,这些神经网络完全覆盖任务集,并在给定的计算预算下最大化任务性能。
即在网络中包含一个额外的任务可以潜在地提高其他任务的准确性,即使添加的任务的性能可能很差。这可以被视为通过添加额外的损失来引导一项任务的损失。
两个贡献:
- 对影响多任务学习的许多因素进行了实证研究,包括网络大小、数据集大小以及一起学习时任务如何相互影响。
- 概述了一个将任务分配给网络的框架,以便在有限的推理时间预算下实现最佳的总预测精度。
Experimental Setup
data set:
Taskonomy dataset: largest multi-task dataset for computer vision with diverse tasks.
task set
这个数据集中选择了两组,每组五个任务。
任务集包括语义分割、深度估计、表面法线预测、surface 关键点检测和 Canny 边缘检测。 包括一项语义任务、两项 3D 任务和两项 2D 任务。
Architectures:
a standard encoder-decoder architecture with a modified Xception (Chollet, 2017)) encoder
Study of Task Relationships
整体来看多任务模型因为大幅降低了模型计算量,所以在多任务集成到一个网络后掉点十分严重,但是如果是多任务模型计算量与单模型计算量总和一致(任务数为 n,多任务计算量为 SNT,单任务计算量为 SNT/n)的情况下,多任务模型其实是能涨点的。
- 不同任务间的关系和训练 setup 相关
- 数据量和模型容量都会影响任务间的关系
- 多任务训练和迁移学习中的各个任务的关系没有明显关系
- normal task 能提升其他任务精度,16 个模型中 15 个精度都提升了(这可能是因为法线在曲面上具有统一的值,并保留三维边),但是 norm task 自己的精度会降低
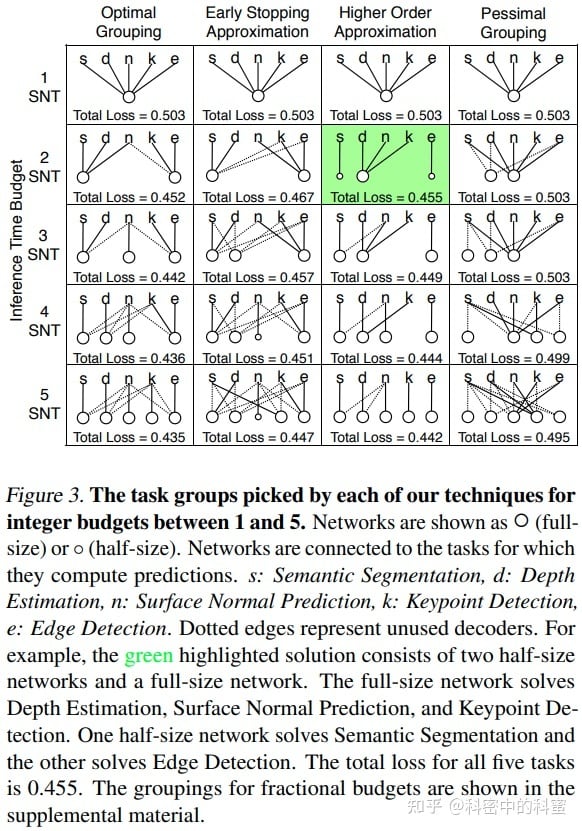
Terminology
请问如何理解迁移学习中的负迁移,有哪些资料阐述了这一问题?
https://www.zhihu.com/question/66492194/answer/242870418
Multi-task Learning and Beyond: 过去,现在与未来
https://zhuanlan.zhihu.com/p/138597214
Hard-parameter sharing & soft-parameter sharing
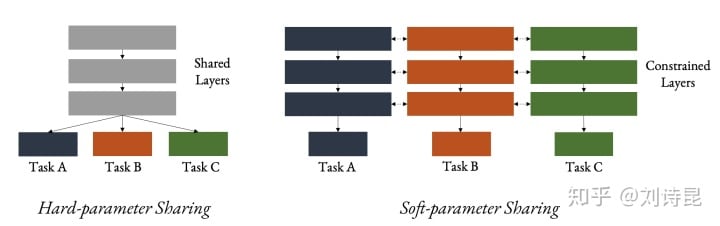
任一 MTL 网络设计可以看做是找 hard 和 soft parameter sharing 的平衡点:1. 如何网络设计可以小巧轻便。2. 如何网络设计可以最大幅度的让不同任务去共享信息。
MTL network design is all about sharing.
